

ChatGPT最近被微软内部禁用
文章来源:机器之心
我们知道,ChatGPT 的成功离不开 RLHF 这个「秘密武器」。不过 RLHF 并不是完美无缺的,存在难以处理的优化难题。本文中,斯坦福大学等研究机构的团队探索用「对比偏好学习」替换掉「强化学习」,在速度和性能上都有不俗的表现。

图片来源:由无界 AI生成
在模型与人类意图对齐方面,根据人类反馈的强化学习(RLHF)已经成为一大流行范式。通常来说,RLHF 算法的工作过程分为两个阶段:一、使用人类偏好学习一个奖励函数;二、通过使用强化学习优化所学习的奖励来对齐模型。
RLHF 范式假定人类偏好的分布遵照奖励,但近期有研究认为情况并非如此,人类偏好其实遵循用户最优策略下的后悔值(regret)。因此,根据反馈学习奖励函数不仅基于一个有漏洞的对于人类偏好的假设,而且还会导致出现难以处理的优化难题 —— 这些难题来自强化学习阶段的策略梯度或 bootstrapping。
由于存在这些优化难题,当今的 RLHF 方法都会将自身限定在基于上下文的 bandit 设置中(比如在大型语言模型中)或会限制自己的观察维度(比如基于状态的机器人技术)。
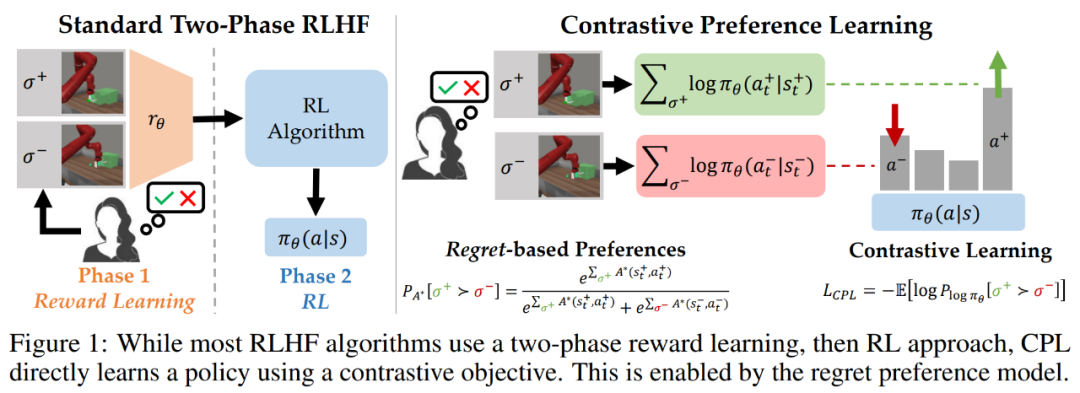
为了克服这些难题,斯坦福等多所大学的一个研究团队提出了一系列新算法,可使用基于后悔的人类偏好模型来优化采用人类反馈时的行为,而没有采用社区广泛接受的仅考虑奖励总和的部分回报模型。不同于部分回报模型,基于后悔的模型可直接提供有关最优策略的信息。
这样一种机制带来了一个幸运的结果:完全不需要强化学习了!
这样一来,就能在具有高维状态和动作空间的通用型 MDP 框架中来解决 RLHF 问题了。
研究者提出,他们这项研究成果的核心见解是:将基于后悔的偏好框架与最大熵(MaxEnt)原理结合起来,可得到优势函数与策略之间的双射。通过将对优势的优化换成对策略的优化,可以推导出一个纯监督学习的目标,其最优值为专家奖励下的最优策略。该团队将这种方法命名为对比偏好学习(Contrastive Preference Learning/CPL),因为其类似于人们广为接受的对比学习目标。

相比于之前的方法,CPL 有三大关键优势。
一、CPL 能像监督学习一样扩展,因为它只使用监督式目标来匹配最优优势,而无需使用任何策略梯度或动态规划。
二、CPL 是完全离策略的方法,因此其可有效使用任何离线的次优数据源。
三、CPL 可应用于任意马尔可夫决策过程(MDP),使其可以从序列数据上的偏好查询中学习。
该团队表示,之前的 RLHF 方法都无法同时满足以上三点。为了表明 CPL 方法符合以上三点描述,研究者进行了实验,结果表明该方法确实能有效应对带有次优和高维离策略数据的序列决策问题。
值得注意的是,他们在实验中发现:在 MetaWorld 基准上,CPL 竟能有效地使用与对话模型一样的 RLHF 微调流程来学习在时间上扩展的操作策略。
具体来说,他们使用监督学习方法,在高维图像观察上对策略进行预训练,然后使用偏好来对其进行微调。无需动态规划或策略梯度,CPL 就能达到与基于先验式强化学习的方法一样的性能表现。与此同时,CPL 方法要快 1.6 倍,参数效率也提高了四倍。当使用更密集的偏好数据时,CPL 的性能表现在 6 项任务的 5 项上超越了强化学习。
对比偏好学习
这种方法的核心思想很简单:研究者发现,当使用最大熵强化学习框架时,后悔偏好模型中使用的优势函数可被轻松替换成策略的对数概率。但是,这种简单的替换能带来巨大的好处。如果使用策略的对数概率,就不需要学习优势函数或应付与类强化学习算法相关的优化难题了。
研究者表示,这不仅能造就对齐更紧密的后悔偏好模型,还能完全依靠监督学习来学习人类反馈。
下面首先将推导 CPL 目标,并表明对于带有无界数据的专家用户奖励函数 r_E,该方法可以收敛到最优策略。然后将说明 CPL 与其它监督学习方法的联系。最后,研究者将说明如何在实践中使用 CPL。他们表示,这些算法属于一个用于解决序列决策问题的新方法类别,这类方法非常高效,因为它能直接从基于后悔的偏好中学习出策略,而无需强化学习。
从最优优势到最优策略
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

